Nessa altura do campeonato todo mundo já sabe o que é Web Scraping, Scraping ou Data Scraping, mas vamos lá: É a varredura de um site ou de outro programa para extração de dados. Fiz isso a vida toda, aliás, meu primeiro estágio em 2002 envolvia muito disso, Eu pegava os dados de sites como Guia Mais, Listas OESP, etc, fazia o tratamento das informações e colocava em um mapa no qual os Gênios do Marketing utilizavam as informações pra fazer análises inteligentes de ações de marketing em áreas específicas. Eu achava o máximo!
Há a discussão se isso é legal ou não é legal, mas os dados estão abertos na internet e se não há nada especificado nos termos de uso do site então você pode sim fazer o data scraping. Inclusive o próprio Buscapé começou assim.
Um desses dias procurei na internet por alguma lista de e-commerces brasileiros e não achei nada, então pensei em ver se tinha alguma coisa no buscapé, já que ele agrega dezenas de e-commerces. Bom, achei essa página aqui que possui as informações das lojas cadastradas no buscapé: http://www.buscape.com.br/pesquise-uma-loja.html?pg=1. Esse pg na query string é o número da página que estamos, obviamente.
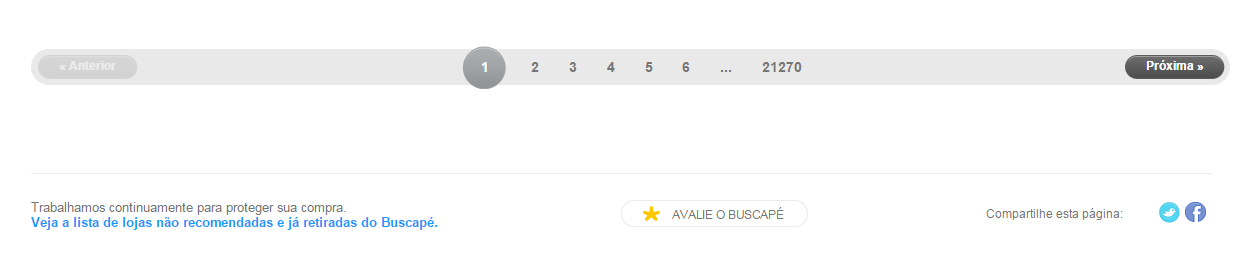
Essa é a carinha da página:

Você pode ver que essa página é uma lista paginada das lojas cadastradas no buscapé. E isso se segue até a página 21270 mostrando 12 empresas por página.
E pra cada e-commerce que você clicar você vai ver várias informações sobre a empresa:
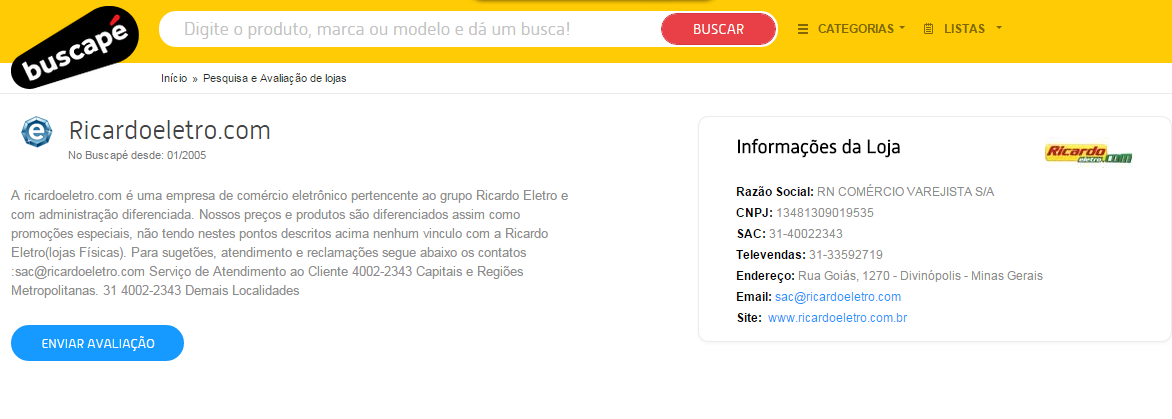
Até aí, tudo fácil. Só achei a página com a lista de empresas, vi que ela tem uma paginação da página 1 até a página 21270, contém 12 lojas por página e que pra pegar as informações completas é necessário entrar no link de cada uma das lojas. Esse é o algoritmo, agora pra fazer isso acontecer tem que criar o script python.
Eu decidi criar 2 scripts, um para pegar o link de todas as lojas de cada uma das páginas da lista e o segundo para entrar em cada link de empresa e retirar essas informações colocando num Excel gigantesco.
Então, organizando, o primeiro script faz isso aqui:
- Encontrar qual elemento da página de listagem contém o link para as lojas
- Varrer todas as páginas de listagem para pegar os links individuais de cada página de loja
- Salvar esses links em um arquivo Excel (pode fazer de qquer outro jeito, eu quis assim)
Primeiro de tudo, você precisa encontrar na estrutura da página os elementos HTML e CSS que contêm os links que precismos retirar. Eu usei o Dev Tools do Chrome pra inspecionar o elemento e vi que todas as lojas estão em uma DIV que contém uma classe chamada size1of3 e é essa classe que vou utilizar para pegar todas as lojas. Dê uma olhada na figura:
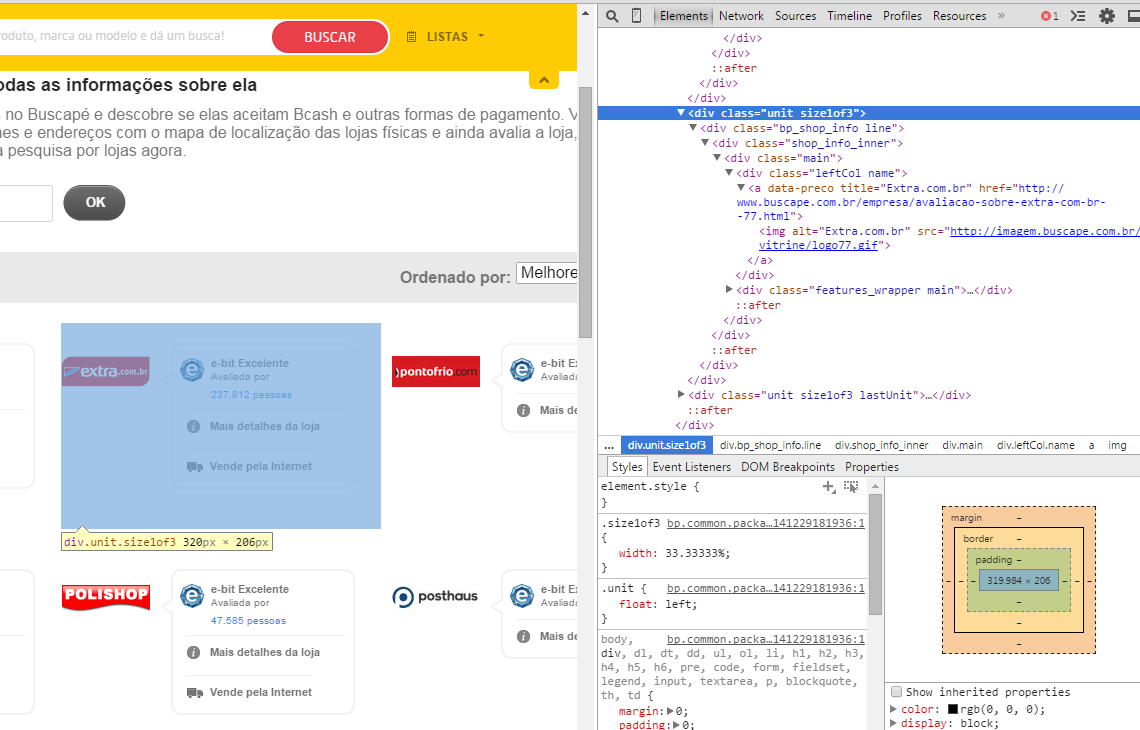
O trecho HTML das divs é normalmente assim:
<div class="unit size1of3">
<div class="bp_shop_info line">
<div class="shop_info_inner">
<div class="main">
<div class="leftCol name">
<a data-preco="" title="Extra.com.br" href="http://www.buscape.com.br/empresa/avaliacao-sobre-extra-com-br--77.html">
<img alt="Extra.com.br" src="http://imagem.buscape.com.br/vitrine/logo77.gif">
</a>
</div>
<div class="features_wrapper main">
<div class="line">
<div class="speech_bubble_pointer">
</div>
<div class="inner">
<div class="features_list main rounded_corner radius10">
<ul class="features_inner">
<li class="info_ebit_rating line">
<a class="ico_ebit sprite_ico ebit_40 leftCol" title="Loja e-bit Excelente" target="_blank" href="http://www.ebit.com.br/lojas_virtuais/html/rateloja.asp?PnumNumEmpresa=2043">
Loja E-bit e-bit Excelente
</a>
<div class="main">
<a class="info_ebit ebit_ajuda" title="Loja e-bit Excelente" target="_blank" href="http://www.ebit.com.br/lojas_virtuais/html/rateloja.asp?PnumNumEmpresa=2043">
e-bit Excelente
</a>
<span class="ratings">
Avaliada por
<a href="http://www.buscape.com.br/empresa/avaliacao-sobre-extra-com-br--77.html">
237.812 pessoas
</a>
</span>
</div>
</li>
<li>
<a title="Clique para ver mais informações" target="_blank" href="http://www.buscape.com.br/empresa/avaliacao-sobre-extra-com-br--77.html" class="sprite_ico info_shop">
Mais detalhes da loja
</a>
</li>
<li class="sprite_ico operation_area">
Vende pela Internet
</li>
</ul>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
Dentro dessa div nós podemos pegar o primeiro link que aparece e extrair dele o title, que é o nome da loja e o href com o link para a página específica daquela loja. Eu escrevi isso em javascript mesmo, testei no Console e vi que funcionava
$('.size1of3').each(function() {var x = $(this).find('a:first');console.log(x.attr('title') + ' ' + x.attr('href'))});
Agora vamos escrever o script em Python!
#URL http://www.buscape.com.br/pesquise-uma-loja.html?pg=1
#from 1 to 21265
# $('.size1of3').each(function() {var x = $(this).find('a:first');console.log(x.attr('title') + ' ' + x.attr('href'))});
import requests
import bs4
import openpyxl
import logging
from openpyxl import Workbook
#iniciar o arquivo de log
logging.basicConfig(filename='arq_links.log',level=logging.WARNING)
#iniciar a planilha do excel otimizada para escrita
wb = Workbook(write_only = True)
ws = wb.create_sheet()
for i in range(1,21266):
try:
payload = {'pg':str(i)}
response = requests.get('http://www.buscape.com.br/pesquise-uma-loja.html', params = payload)
soup = bs4.BeautifulSoup(response.text)
for div in soup.find_all(class_='size1of3'):
ws.append([
div.find('a')['title'],
div.find('a')['href'],
'http://www.buscape.com.br/pesquise-uma-loja.html?pg=%s' % i,
i,
])
print "#%s" % i,
except Exception as err:
print "Erro na pagina %s" % i
logging.exception(u"Erro na pagina %s" % i)
wb.save('lojas.xlsx')
Estou usando o requests pra dar o GET na página e sempre passo como a query string (a variável payload) a página que quero dar GET.
payload = {'pg':str(i)}
response = requests.get('http://www.buscape.com.br/pesquise-uma-loja.html', params = payload)
Eu faço agora o parse desse resultado que vem no response.text usando o Beautiful Soup pra pegar apenas as informações que eu quero, no caso o nome da loja e o link para a página individual dela. Também resolvi salvar o link da página em que estou.
soup = bs4.BeautifulSoup(response.text)
for div in soup.find_all(class_='size1of3'):
ws.append([
div.find('a')['title'],
div.find('a')['href'],
'http://www.buscape.com.br/pesquise-uma-loja.html?pg=%s' % i,
i,
])Estou usando o openpyxl que é excelente pra criar arquivos XLSX e também resolvi criar um log pra ver quais páginas podem ter dado errado por algum motivo. Assim é possível ver quais páginas ficaram de fora da sua lista e rodá-las novamente.
Enfim, rodando esse arquivo temos como saída um arquivo chamado lojas.xlsx com a lista de todas as lojas e com os links para a página individual delas. Então a parte um foi concluída, agora só falta entrar em cada uma dessas lojas e pegar os dados delas.
O segundo script deve fazer isso aqui:
- Vamos verificar como é o HTML + CSS de cada página de loja para saber como vamos fazer o scraping.
- Ler o arquivo excel gerado pelo primeiro script que contém o link de cada loja.
- Entrar em cada página e pegar os dados relevantes disponíveis
- Salvar tudo em um XLSX gigante
Pra verificar o formato HTML a gente pode inspecionar o elemento de novo dentro da página da loja. O que dá pra ver é que a div principal que contém os dados tem a classe company-header. Nessa div você pode pegar a classificação Ebit da loja, a descrição da loja e uma lista de informação de contatos que não é a mesma para todos os contatos, alguns tem informação como e-mail, telefone e outros não, então vamos ter que driblar (“Dibrar”) isso.
O bom é que todas essas informações de contato estão em uma lista e podemos pegar todos os elementos <li> desta lista e salvar em uma lista python. Depois podemos parsear essas informações e colocá-las em colunas certinhas num banco de dados, por enquanto só vou focar em pegar os dados.
O script fica assim:
import requests
import bs4
import openpyxl
import logging
from openpyxl import load_workbook
from openpyxl import Workbook
#iniciar o arquivo de log
logging.basicConfig(filename='arq_lojas.log',level=logging.WARNING)
#Abrindo o excel de leitura
wb = load_workbook(filename = 'lojas.xlsx', use_iterators = True)
ws = wb.get_sheet_by_name(name = 'Sheet1')
#iniciar a planilha do excel de excrita
wb_escrita = Workbook(write_only = True)
ws_escrita = wb_escrita.create_sheet()
for row in ws.iter_rows():
try:
nome = row[0].value
url = row[1].value
response = requests.get(url)
soup = bs4.BeautifulSoup(response.text)
div = soup.find(class_='company-header')
ebit = ''
if div.find('img'):
if div.find('img').has_attr('title'):
ebit = div.find('img')['title']
desc = div.find(class_='about').string
div = soup.find(class_='company-contacts')
lista = []
for li in div.find_all('li'):
lista.append (li.text)
ws_escrita.append(
[nome,
url,
ebit,
desc] + lista #Adicionando a lista de contatos daquela loja
)
except Exception as err:
print "Erro na pagina %s" % url
logging.exception(u"Erro na pagina %s" % url)
wb_escrita.save('lojas_final.xlsx')Ficou bem parecido com o primeiro arquivo. Agora é só executar os scripts. Execute o primeiro, ele vai demorar algumas horas até terminar, depois execute o segundo script. Aqui demorou bastante, quase 20 horas pra executar tudo.
O resultado final com os arquivos de excel e o código fonte você pode ver aqui no meu github: https://github.com/ffreitasalves/buscape-scraper